

pandas.concat
pandas는 조인/병합 유형 작업의 경우 인덱스 및 관계 대수 기능에 대한 다양한 종류의 집합 논리와 함께 Series 또는 DataFrame을 쉽게 결합할 수 있는 다양한 기능을 제공한다. concat 외에도 merge, join 등의 함수도 있으나, 먼저 concat을 살펴보도록 한다.
concat은 DataFrame을 물리적으로 이어붙이는 기능을 한다. 옵션(매개 변수)에 따라 합치는 방법이나 결과가 다양해지기 때문에, 원하는 방식에 맞게 옵션을 선택해서 사용해야 한다.
공식 문서 https://pandas.pydata.org/docs/reference/api/pandas.concat.html
parameter(매개 변수) 살펴보기
모든 매개 변수 및 기본 default 설정
pandas.concat(
objs,
axis=0,
join="outer",
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
sort=False,
copy=True,
)import pandas as pd
df1 = pd.DataFrame({'id': [1, 2], 'name': ['홍길동', '김철수']})
df2 = pd.DataFrame({'id': [2, 3, 4], 'nickname': ['csKim', 'yhLee', 'syLim']})
objs
결합하기를 원하는 Series나 DataFrame 개체들의 시퀀스 또는 매핑
axis
결합하고자 하는 축
- 0 : index(행) - default
pd.concat([df1, df2], axis=0)
- 1 : columns(열)
pd.concat([df1, df2], axis=1)
join
다른 축의 인덱스를 처리하는 방법
- inner : 공통 column에 대해서만 합치기
pd.concat([df1, df2], join='inner')
- outer : 모든 column에 대해서 합치기 - default
pd.concat([df1, df2], join='outer')
ignore_index
- True : 합치면서 인덱스 무시
pd.concat([df1, df2], ignore_index=True)
- False : 인덱스 유지 - default
keys
합친 데이터 프레임에 keys(시퀀스)로 가장 바깥에 계층적 인덱스 구현
pd.concat([df1, df2], keys=['df1', 'df2'])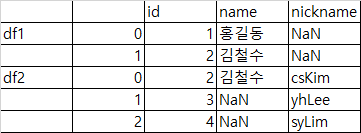
levels
다른 레벨을 지정하고 싶을 때 사용(가끔 있는 경우)
MultiIndex를 구성하는 데 사용할 특정 수준(고유 값), 지정하지 않으면 키에서 추론
pd.concat([df1, df2], keys=['df1', 'df2']).index.levelsoutput >>> [['df1', 'df2'], [0, 1, 2]]
names
결과적인 계층적 인덱스 내 levels의 이름
pieces = {"x": df1, "y": df2}
result = pd.concat(
pieces, keys=["x", "y"], levels=[["y", "x"]], names=["group_key"]
)
print(result.index.levels)
output >>> [['y', 'x'], [0, 1, 2]]
levels & names는 상당히 난해하지만 범주형 변수의 순서가 의미 있는 GroupBy와 같은 것을 구현하는 데 실제로 필요
verify_integrity
결합 시 같은 이름의 index 중복을 확인
- True : index 중복 막음(에러 생성)
pd.concat([df1, df2], verify_integrity=True)output >>> ValueError: Indexes have overlapping values: Int64Index([0, 1], dtype='int64')
- False - default
sort
아직 정렬되지 않은 경우 연결되지 않은 축을 정렬
- True
pd.concat([df1, df2], sort=True)
- False - default
copy
- False : 불필요한 데이터 복사 막음
pd.concat([df1, df2], copy=False)- True - default
'Python' 카테고리의 다른 글
| [python] DataFrame 결합 - pandas.DataFrame.join (0) | 2023.08.02 |
|---|---|
| [python] DataFrame 결합 - pandas.merge (0) | 2023.07.31 |
| [python] ast.literal_eval VS eval 비교하기 (0) | 2023.07.26 |
| [python] csv 모듈 사용하기 (0) | 2023.07.25 |
| [python] APScheduler 사용하기 (1) | 2023.07.20 |