

Pandas.DataFrame.join
pandas는 조인/병합 유형 작업의 경우 인덱스 및 관계 대수 기능에 대한 다양한 종류의 집합 논리와 함께 Series 또는 DataFrame을 쉽게 결합할 수 있는 다양한 기능을 제공한다. 저번 글에서는 merge에 대해 다루어봤는데, merge가 join보다 세세한 설정이 가능하고 따로 설정을 하지 않아도 겹치는 열을 찾아 합쳐준다면 join은 index 설정을 해주어야 깔끔한 결합이 가능하다. join은 merge 함수를 기반으로 만들어졌기 때문에 기본 작동 방식이 비슷할 수 있다. 그럼 오늘은 join에 대해 살펴보자.
공식 문서 https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.join.html
pandas.concat 포스팅 https://im-so-so.tistory.com/99
pandas.merge 포스팅 https://im-so-so.tistory.com/100
parameter(매개변수 살펴보기)
모든 매개 변수 및 기본 default 설정
DataFrame.join(
other,
on=None,
how='left',
lsuffix='',
rsuffix='',
sort=False,
validate=None,
)import pandas as pd
df1 = pd.DataFrame({'name': ['홍길동', '김철수', '박유진']}, index=[1, 2, 5])
df2 = pd.DataFrame({'nickname': ['gdHong', 'csKim', 'yhLee', 'syLim']}, index=[1, 2, 3, 4])
other
합칠 개체, 데이터 프레임, 시리즈, 혹은 이들의 조합을 포함하는 리스트
df1.join(df2)
on
other의 인덱스에 조인할 열 또는 인덱스 이름, on=None인 경우 인덱스-온-인덱스에 조인
how
조인할 방법의 유형
- left : 호출 프레임의 인덱스(또는 on이 지정된 경우 열) 사용 - default
- right : other의 인덱스 사용
df1.join(df2, how='right')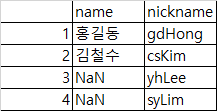
- inner : 호출 프레임의 인덱스(또는 on이 지정된 경우 열)와 other의 인덱스의 교집합 형성, 호출 프레임의 순서를 유지
df1.join(df2, how='inner')
- outer : 호출 프레임의 인덱스(또는 on이 지정된 경우 열)를 other의 인덱스와 합집합을 형성하고 사전순 정렬
df1.join(df2, how='outer')
- cross : 두 프레임에서 데카르트 곱을 생성하고 왼쪽 키의 순서를 유지
df1.join(df2, how='cross')
lsuffix, rsuffix
병합 시 겹치는 column명을 구분할 때 사용, 각 요소가 호출 프레임과 other의 각각 겹치는 column명에 추가할 접미사
df1 = pd.DataFrame({'name': ['홍길동', '김철수', '박유진']}, index=[1, 2, 5])
df2 = pd.DataFrame({'name': ['gdHong', 'csKim', 'yhLee', 'syLim']}, index=[1, 2, 3, 4])
df1.join(df2, lsuffix='_x', rsuffix='_y')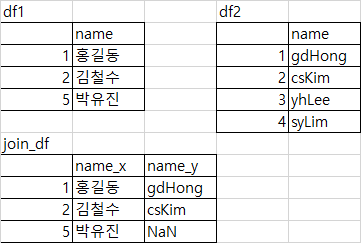
sort
- True : 결합한 DataFrame의 join key 기준 사전 순으로 정렬
- False : how 변수에 따라 정렬이 달라진다. - default
validate
지정한 병합 방식이 맞는지 검증하고 싶은 경우 사용, 병합 방식이 다를 경우 오류 생성
- "one_to_one" 또는 "1:1" : left 및 right 데이터에서 병합 키가 고유한지 확인
- "one_to_many" 또는 "1:m" : 병합 키가 left 데이터에서 고유한지 확인
- "many_to_one" 또는 "m:1" : 병합 키가 right 데이터에서 고유한지 확인
- "many_to_many" 또는 "m:m" : 허용되지만 확인되지 않음
df1 = pd.DataFrame({'id': [1, 2, 2], 'name': ['홍길동', '김철수', '박유진']})
df2 = pd.DataFrame({'id': [1, 2, 3, 4], 'nickname': ['gdHong', 'csKim', 'yhLee', 'syLim']})
df1.join(df2.set_index('id'), on='id', validate='1:m')output >>> pandas.errors.MergeError: Merge keys are not unique in left dataset; not a one-to-many merge
df1 = pd.DataFrame({'id': [1, 2, 2], 'name': ['홍길동', '김철수', '박유진']})
df2 = pd.DataFrame({'id': [1, 2, 3, 4], 'nickname': ['gdHong', 'csKim', 'yhLee', 'syLim']})
df1.join(df2.set_index('id'), on='id', validate='m:1')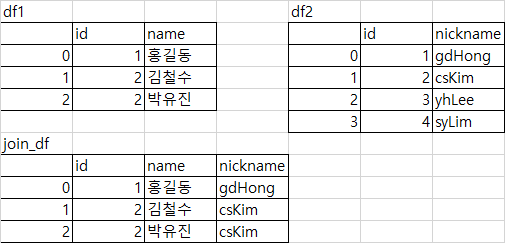
'Python' 카테고리의 다른 글
| [python] DatetimeIndex 만들기 - pandas.date_range (0) | 2023.08.03 |
|---|---|
| [python error] SQL syntax error 1064 (0) | 2023.08.02 |
| [python] DataFrame 결합 - pandas.merge (0) | 2023.07.31 |
| [python] DataFrame 결합 - pandas.concat (0) | 2023.07.28 |
| [python] ast.literal_eval VS eval 비교하기 (0) | 2023.07.26 |