

datetime resample, groupby with Grouper
datetime 행을 내가 원하는 간격(하루, 일주일 등)으로 모아서 합을 구하거나, 평균을 구하고 싶은 경우가 있다. groupby를 사용하면 되겠지 싶었지만 편리하게 사용하기 좋은 함수가 있어서 소개하고자 한다. 특히 datetime을 처리하는 데 있어서는 pandas.DataFrame.resample과 pandas.Grouper 함수를 활용해보는 것을 추천한다. 두 함수는 매개변수부터 사용법까지 거의 유사하기 때문에 어떤 매개변수가 어떤 역할을 하는지만 알아둔다면 둘 다 편하게 사용 가능하다.
pandas.DataFrame.resample
시계열 데이터의 빈도 변환 및 리샘플링을 위한 편리한 방법이다. 공식 문서를 활용하여 다양한 방법으로 시도해보면 어떤 식으로 사용해야 할지 알 수 있다.
공식 문서 https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.resample.html
모든 매개 변수 및 기본 default 설정
DataFrame.resample(
rule,
axis=0,
closed=None,
label=None,
convention='start',
kind=None,
on=None,
level=None,
origin='start_day',
offset=None,
group_keys=False
)
pandas.Grouper
pandas.Grouper를 사용하면 사용자가 개체에 대한 groupby 명령을 지정할 수 있다. 공식 문서를 활용하여 다양한 방법으로 시도해보면 어떤 식으로 사용해야 할지 알 수 있다.
공식 문서 https://pandas.pydata.org/docs/reference/api/pandas.Grouper.html
모든 매개 변수 및 기본 default 설정
pandas.Grouper(
key=None,
level=None,
freq=None,
axis=0,
sort=False,
closed=None,
label=None,
convention=None,
origin='start_day',
offset=None,
dropna=True
)
예시1
import pandas as pd
df = pd.DataFrame(
{'reg_date': pd.date_range(start='2023-08-01', periods=9, freq='H'),
'value': list(range(9))}
)
- 0시~8시의 데이터를 3시간 간격으로 모아 value 합 구하기
df.resample('3H', on='reg_date').sum()df.groupby(pd.Grouper(key='reg_date', freq='3H')).sum()output >>> df index 0~2 / 3~5 / 6~8 로 묶임
value
reg_date
2023-08-01 00:00:00 3
2023-08-01 03:00:00 12
2023-08-01 06:00:00 21
- 위의 조건 + 구간의 끝을 포함하며 라벨을 구간의 끝으로 지정
df.resample('3H', on='reg_date', label='right', closed='right').sum()df.groupby(pd.Grouper(key='reg_date', freq='3H', label='right', closed='right')).sum()output >>> df index 0 / 1~3 / 4~6 / 7~8 로 묶임
value
reg_date
2023-08-01 00:00:00 0
2023-08-01 03:00:00 6
2023-08-01 06:00:00 15
2023-08-01 09:00:00 15
예시2
import pandas as pd
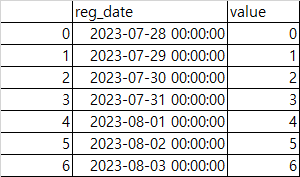
df = pd.DataFrame(
{'reg_date': pd.date_range(start='2023-07-28', end='2023-08-03', freq='D'),
'value': list(range(7))}
)
- 7월 28일~8월 3일의 데이터를 주 단위(일요일 기준)로 모아 평균 구하기
df.resample('W', on='reg_date').mean()df.groupby(pd.Grouper(key='reg_date', freq='W')).mean()output >>> df index 0~2 / 3~6 로 묶임
value
reg_date
2023-07-30 1.0
2023-08-06 4.5
- 7월 28일~8월 3일의 데이터를 주 단위(목요일 기준)로 모아 평균 구하기, 라벨은 구간의 처음으로 지정
df.resample('W-THU', on='reg_date', label='left').mean()df.groupby(pd.Grouper(key='reg_date', freq='W-THU', label='left')).mean()output >>> df index 0~6 로 묶임
value
reg_date
2023-07-27 3.0
- 7월 28일~8월 3일의 데이터를 달 단위로 모아 구간의 끝을 포함하여 평균 구하기
df.resample('M', on='reg_date', closed='right').mean()df.groupby(pd.Grouper(key='reg_date', freq='M', closed='right')).mean()output >>> df index 0~3 / 4~6 로 묶임
value
reg_date
2023-07-31 1.5
2023-08-31 5.0
예시3
origin
그룹화를 조정할 타임스탬프 혹은 문자열 값으로, 시간 그룹화의 기준이 된다.
origin 시간대(timezone)는 인덱스의 시간대와 일치해야 한다. 문자열인 경우 다음 중 하나로 설정 가능하다.
- epoch : origin = 1970-01-01
- start : origin = 타임 시리즈의 첫번째 값
- start_day : origin = 타임 시리즈의 첫번째 날 0시 - default
- end : origin is the last value of the timeseries = 타임 시리즈의 마지막 값
- end_day : origin is the ceiling midnight of the last day = 타임 시리즈의 마지막 다음 날 0시
import pandas as pd
df = pd.DataFrame(
{'reg_date': pd.date_range(start='2023-08-01', periods=9, freq='7T'),
'value': list(range(9))}
)
- 데이터를 10초 단위로 모아 합 구하기
df.resample('10T', on='reg_date').sum()df.groupby(pd.Grouper(key='reg_date', freq='10T')).sum()output >>> df index 0~1 / 2 / 3~4 / 5 / 6~7 / 8 로 묶임
value
reg_date
2023-08-01 00:00:00 1
2023-08-01 00:10:00 2
2023-08-01 00:20:00 7
2023-08-01 00:30:00 5
2023-08-01 00:40:00 13
2023-08-01 00:50:00 8
- 데이터를 13초 단위로 모아 합 구하기, orgin은 epoch로 지정
df.resample('13T', on='reg_date', origin='epoch').sum()df.groupby(pd.Grouper(key='reg_date', freq='13T', origin='epoch')).sum()output >>> df index 0 / 1~2 / 3 / 4~5 / 6~7 / 8 로 묶임
value
reg_date
2023-07-31 23:49:00 0
2023-08-01 00:02:00 3
2023-08-01 00:15:00 3
2023-08-01 00:28:00 9
2023-08-01 00:41:00 13
2023-08-01 00:54:00 8
- 데이터를 13초 단위로 모아 합 구하기, origin은 end로 지정
df.resample('13T', on='reg_date', origin='end').sum()df.groupby(pd.Grouper(key='reg_date', freq='13T', origin='end')).sum()output >>> df index 0 / 1~2 / 3~4 / 5~6 / 7~8 로 묶임
value
reg_date
2023-08-01 00:04:00 0
2023-08-01 00:17:00 3
2023-08-01 00:30:00 7
2023-08-01 00:43:00 11
2023-08-01 00:56:00 15
- 데이터를 13초 단위로 모아 합 구하기, origin은 end_day로 지정
df.resample('13T', on='reg_date', origin='end_day').sum()df.groupby(pd.Grouper(key='reg_date', freq='13T', origin='end_day')).sum()output >>> df index 0~1 / 2~3 / 4~5 / 6~7 / 8 로 묶임
value
reg_date
2023-08-01 00:10:00 1
2023-08-01 00:23:00 5
2023-08-01 00:36:00 9
2023-08-01 00:49:00 13
2023-08-01 01:02:00 8
'Python' 카테고리의 다른 글
| [python] 동적 변수명 - globals(), locals() (0) | 2023.08.11 |
|---|---|
| [python error] pandas.read_excel TypeError: got an unexpected keyword argument (1) | 2023.08.08 |
| [python] pandas.DataFrame.round 반올림 (0) | 2023.08.06 |
| [python] SQL select query by date (0) | 2023.08.05 |
| [python] datetime columns difference 구하기 (0) | 2023.08.04 |