[python] DataFrame 결합 - pandas.merge

pandas.merge
pandas는 조인/병합 유형 작업의 경우 인덱스 및 관계 대수 기능에 대한 다양한 종류의 집합 논리와 함께 Series 또는 DataFrame을 쉽게 결합할 수 있는 다양한 기능을 제공한다. 저번 글에서는 concat에 대해 다루어봤는데, 조금 다른 결인 merge를 살펴보고자 한다.
pandas.merge는 두 데이터프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합할 때 사용한다. 옵션(매개 변수)에 따라 합치는 방법이나 결과가 다양해지기 때문에, 원하는 방식에 맞게 옵션을 선택해서 사용해야 한다.
공식 문서 https://pandas.pydata.org/docs/reference/api/pandas.merge.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html#pandas.DataFrame.merge
pandas.concat 포스팅 https://im-so-so.tistory.com/99
parameter(매개 변수) 살펴보기
모든 매개 변수 및 기본 default 설정
pd.merge(
left,
right,
how="inner",
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=False,
suffixes=("_x", "_y"),
copy=True,
indicator=False,
validate=None,
)import pandas as pd
df1 = pd.DataFrame({'id': [1, 2], 'name': ['홍길동', '김철수']})
df2 = pd.DataFrame({'id': [1, 2, 3], 'nickname': ['gdHong', 'csKim', 'yhLee']})
left, right
결합하고자 하는 데이터프레임 혹은 시리즈
how
병합의 유형
- left : SQL left outer 조인과 유사하게 왼쪽 프레임의 키만 사용. 키 순서를 유지
pd.merge(df1, df2, how='left')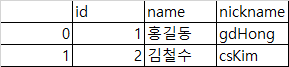
- right : SQL right outer 조인과 유사하게 오른쪽 프레임의 키만 사용. 키 순서를 유지
pd.merge(df1, df2, how='right')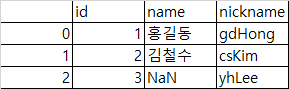
- outer : SQL full outer 조인과 유사하게 두 프레임의 키 조합을 사용. 키를 사전순으로 정렬
pd.merge(df1, df2, how='outer')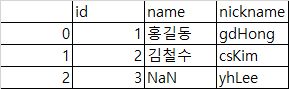
- inner : SQL inner 조인과 유사하게 두 프레임의 키 교차를 사용. 왼쪽 키의 순서를 유지
pd.merge(df1, df2, how='inner')
- cross : 두 프레임에서 데카르트 곱을 생성하고 왼쪽 키의 순서를 유지
pd.merge(df1, df2, how='cross')
on
조인할 열 또는 인덱스 이름
두 DataFrames 모두에서 찾아온 값이어야 하고, on=None이고 인덱스를 병합하지 않는 경우 기본값은 두 DataFrames의 column 교차점이다.
pd.merge(df1, df2, on='id')
left_on, right_on
column 기준으로 결합할 DataFrame들의 key column 이름이 다른 경우 사용, left 또는 right DataFrame에서 조인할 열 또는 인덱스 이름
left 또는 right DataFrame 길이의 배열 또는 배열 목록일 수도 있는데, 이러한 배열은 열인 것처럼 처리한다.
df1 = pd.DataFrame({'id1': [1, 2], 'name': ['홍길동', '김철수']})
df2 = pd.DataFrame({'id2': [1, 2, 3], 'nickname': ['gdHong', 'csKim', 'yhLee']})
pd.merge(df1, df2, left_on='id1', right_on='id2')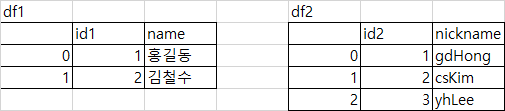

left_index, right_index
index 기준으로 DataFrame을 결합하고 싶은 경우 사용, left 또는 right DataFrame의 인덱스를 조인 키로 사용
MultiIndex인 경우 다른 DataFrame의 키 수(인덱스 또는 열 수)는 레벨 수와 일치해야 한다.
df1 = pd.DataFrame({'id': [1, 2], 'name': ['홍길동', '김철수']})
df2 = pd.DataFrame({'nickname': ['gdHong', 'csKim', 'yhLee']})
pd.merge(df1, df2, left_on='id', right_index=True)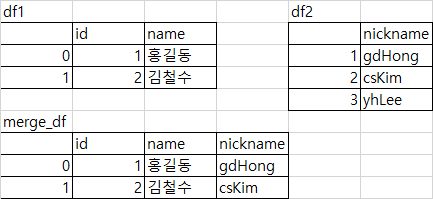
df1 = pd.DataFrame({'name': ['홍길동', '김철수']}, index=[1, 2])
df2 = pd.DataFrame({'id': [1, 2, 3], 'nickname': ['gdHong', 'csKim', 'yhLee']})
pd.merge(df1, df2, left_index=True, right_on='id')
df1 = pd.DataFrame({'name': ['홍길동', '김철수']}, index=[1, 2])
df2 = pd.DataFrame({'nickname': ['gdHong', 'csKim', 'yhLee']}, index=[1, 2, 3])
pd.merge(df1, df2, left_index=True, right_index=True)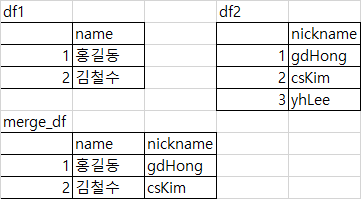
sort
- True : 결합한 DataFrame의 key를 사전 순으로 정렬
- False : how 변수에 따라 정렬이 달라진다. - default
suffixes
병합 시 겹치는 column명을 구분할 때 사용, 각 요소가 left와 right 각각 겹치는 column명에 추가할 접미사를 나타내는 문자열인 길이 2의 시퀀스
문자열 대신 None 값을 전달할 경우 left와 right의 column명을 접미사 없이 그대로 둔다. 값 중 적어도 하나는 None이 아니어야 한다.
df1 = pd.DataFrame({'id1': [1, 2], 'name': ['홍길동', '김철수']})
df2 = pd.DataFrame({'id2': [1, 2, 3], 'name': ['gdHong', 'csKim', 'yhLee']})
pd.merge(df1, df2, left_on='id1', right_on='id2', suffixes("_left", "_right"))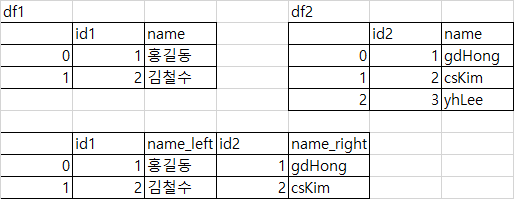
copy
- False : 불필요한 데이터 복사 막음
- True - default
indicator
병합이 어떻게 이루어졌는지에 대한 정보를 표시하고 싶은 경우 사용
- True : 마지막 열에 _merge 라는 이름으로 정보 표시
df1 = pd.DataFrame({'id': [1, 2], 'name': ['홍길동', '김철수']})
df2 = pd.DataFrame({'id': [1, 2, 3], 'nickname': ['gdHong', 'csKim', 'yhLee']})
pd.merge(df1, df2, how='outer', indicator=True)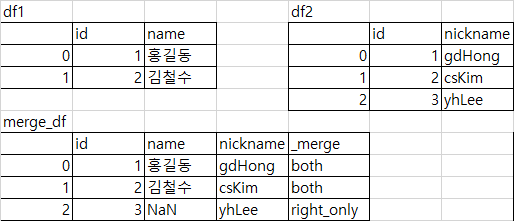
- False - default
validate
지정한 병합 방식이 맞는지 검증하고 싶은 경우 사용, 병합 방식이 다를 경우 오류 생성
- "one_to_one" 또는 "1:1" : left 및 right 데이터에서 병합 키가 고유한지 확인
- "one_to_many" 또는 "1:m" : 병합 키가 left 데이터에서 고유한지 확인
- "many_to_one" 또는 "m:1" : 병합 키가 right 데이터에서 고유한지 확인
- "many_to_many" 또는 "m:m" : 허용되지만 확인되지 않음
df1 = pd.DataFrame({'id': [1, 1, 2], 'name': ['홍길동', '이영희', '김철수']})
df2 = pd.DataFrame({'id': [1, 2, 3], 'nickname': ['gdHong', 'csKim', 'yhLee']})
pd.merge(df1, df2, on='id', validate='1:m')output >>> pandas.errors.MergeError: Merge keys are not unique in left dataset; not a one-to-many merge
df1 = pd.DataFrame({'id': [1, 1, 2], 'name': ['홍길동', '이영희', '김철수']})
df2 = pd.DataFrame({'id': [1, 2, 3], 'nickname': ['gdHong', 'csKim', 'yhLee']})
pd.merge(df1, df2, on='id', validate='m:1')